Introduction: Convolutional neural networks (CNN) have achieved unprecedented success in the field of computer vision, but we still do not have a comprehensive understanding of the reasons for their significant effects. Recently, Isma Hadji and Richard P. Wildes of the Department of Electrical Engineering and Computer Science at York University published the paper "What Do We Understand About Convolutional Networks?", which covers the technical foundation, components, current status, and research prospects of convolutional networks. Carefully introduced our current understanding of CNN.

01 Introduction
1.1 Motivation
Over the past few years, computer vision research has focused mainly on convolutional neural networks (often abbreviated as ConvNet or CNN). These work have achieved new current best performance on a wide range of classification and regression tasks. In contrast, although the history of these methods can be traced back many years ago, the theoretical understanding of the ways in which these systems yield outstanding results is still lagging behind. In fact, many of the current achievements in the field of computer vision are using CNN as a black box. This approach is effective, but the reasons for its effectiveness are very ambiguous, which can not meet the requirements of scientific research. In particular, these two issues can be complementary: (1) What is being studied in the areas of learning (such as the convolution kernel)? (2) In terms of architectural design (such as the number of layers, the number of cores, pooling strategies, non-linear choices), why are some choices better than others? The answers to these questions will not only help improve our scientific understanding of CNN, but also improve their usefulness.
In addition, the current method of implementing CNN requires a large amount of training data, and design decisions have a great influence on the performance of the results. A deeper theoretical understanding should reduce the reliance on data-driven design. Although empirical studies have investigated the way networks have been implemented, these results have so far been limited to the visualization of internal processes to understand what is happening in different layers of CNN.
1.2 Goals
In response to the above, the report will outline the most prominent method of using multi-layer convolution architecture proposed by researchers. It is important to point out that this report will discuss various components of a typical convolutional network by outlining different methods and will introduce the biological discoveries and/or rational theoretical foundations on which their design decisions are based. In addition, this report will also outline the different attempts to understand CNN through visualization and empirical research. The ultimate goal of this report is to explain the role of each of the processing layers involved in the CNN architecture, to bring together our current understanding of CNN and to explain the issues that remain to be resolved.
1.3 Report Outline
The structure of this report is as follows: This chapter gives the motivation to review our understanding of convolutional networks. Chapter 2 will describe various multi-layer networks and give the most successful architecture used in computer vision applications. Chapter 3 will focus more specifically on each building block of a typical convolutional network and will discuss the design of different components from both biological and theoretical perspectives. Finally, Chapter 4 will discuss current trends in CNN design and understanding of CNN's work, and will also highlight some of the key shortcomings that still exist.
02 Multi-layer network
In summary, this chapter will briefly outline the most prominent multi-layer architecture used in the field of computer vision. It should be pointed out that although this chapter covers the most important contributions in the literature, it does not provide a comprehensive overview of these architectures, as they already exist elsewhere (eg [17, 56, 90]). Instead, the purpose of this chapter is to set the basis of discussion for the remainder of this report so that we can show and discuss in detail the current understanding of convolutional networks for visual information processing.
2.1 Multi-layer architecture
Prior to the recent success of deep learning based networks, the most advanced computer vision systems for identification relied on two separate but complementary steps. The first step is to transform the input data into a suitable form through a set of artificially designed operations (such as convolution with the basic set, local or global coding methods). The transformation of the input usually requires finding a compact and/or abstract representation of the input data while also injecting some invariants into the current task. The goal of this transformation is to change the data in a way that is more easily separated by the classifier. Second, the transformed data is often used to train certain types of classifiers (such as support vector machines) to identify the content of the input signal. In general, the performance of any classifier is severely affected by the transformation method used.
The multi-layer learning architecture brings different perspectives to this problem. This architecture proposes not only to learn the classifier but also to directly learn the required transformation operations from the data. This form of learning is often referred to as "characteristic learning," and is referred to as "deep learning" when applied to deep multi-layered architectures.
A multi-tier architecture can be defined as a computing model that allows useful information to be extracted from multi-level abstractions of input data. In general, the design goal of a multi-tier architecture is to highlight important aspects of the input at a higher level, and at the same time become more and more robust in the face of less important changes. Most multi-layer architectures stack simple building blocks with alternating linear and nonlinear functions. Over the years, researchers have proposed many different types of multi-layer architectures. This chapter will cover the most prominent of these architectures used in computer vision applications. Artificial neural network is the focus of attention, because the performance of this architecture is very prominent. For the sake of simplicity, these types of networks will be referred to directly as "neural networks."
2.1.1 Neural Network
A typical neural network consists of an input layer, an output layer, and multiple hidden layers, each of which contains multiple cells.

Figure 2.1: A schematic diagram of a typical neural network architecture, drawing from [17]
An automatic encoder can be defined as a multilayer neural network consisting of two main parts. The first part is an encoder that transforms the input data into feature vectors; the second part is a decoder that maps the generated feature vectors back into the input space.

Figure 2.2: Structure of a typical automatic encoder network, drawing from [17]
2.1.2 Recurrent Neural Network
When it comes to tasks that rely on sequence inputs, the Recurrent Neural Network (RNN) is one of the most successful multi-layer architectures. The RNN can be viewed as a special type of neural network in which each hidden unit's input is the data observed at its current time step and the state of its previous time step.
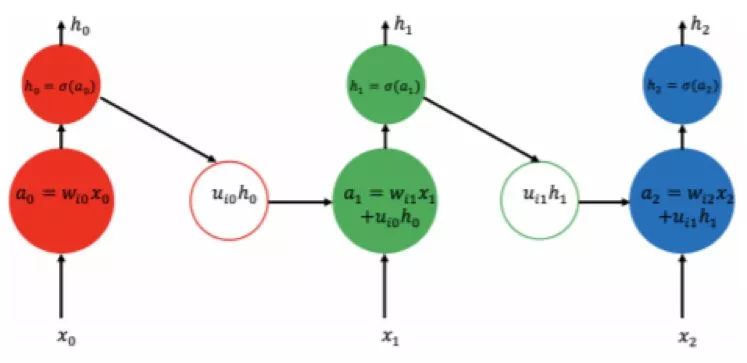
Figure 2.3: Schematic diagram of the operation of a standard recurrent neural network. The input of each RNN unit is the new input of the current time step and the status of the previous time step; then 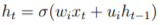 The new output is calculated and this output can in turn be fed to the next level of the multi-level RNN for processing.
The new output is calculated and this output can in turn be fed to the next level of the multi-level RNN for processing.
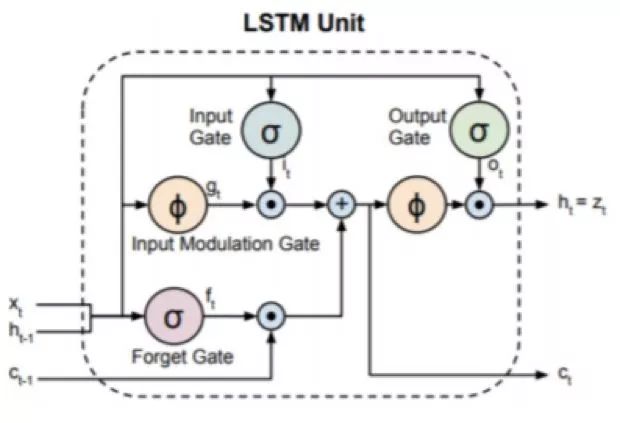
Figure 2.4: Schematic diagram of a typical LSTM unit. The input to the unit is the input of the current time and the input of the previous time, then it will return an output and feed it to the next time. The final output of the LSTM unit is controlled by the input gates, output gates, and memory cell states. Picture from [33]
2.1.3 Convolutional Network
A convolutional network (CNN) is a type of neural network that is particularly suitable for computer vision applications because they can use layered operations to layer and abstract representations. Two key design ideas have contributed to the success of the convolution architecture in computer vision. First, CNN uses the 2D structure of the image, and the pixels in adjacent regions are usually highly correlated. Therefore, CNN does not need to use a one-to-one connection between all pixel units (most neural networks will do this), but can use partial local connections. Second, the CNN architecture relies on feature sharing, so each channel (ie, output feature map) is generated by convolving the same filter at all locations.
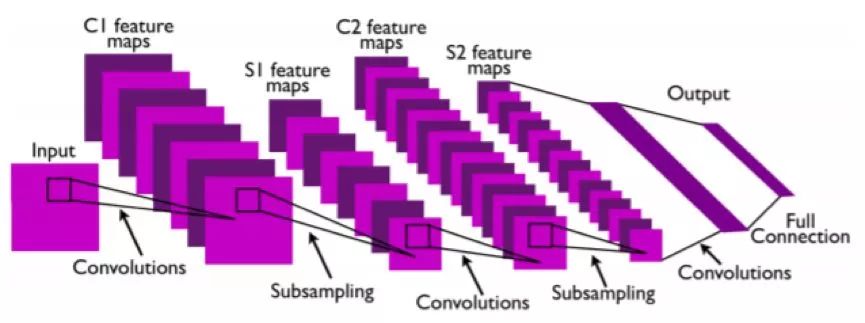
Figure 2.5: Schematic diagram of the structure of a standard convolutional network, drawing from [93]
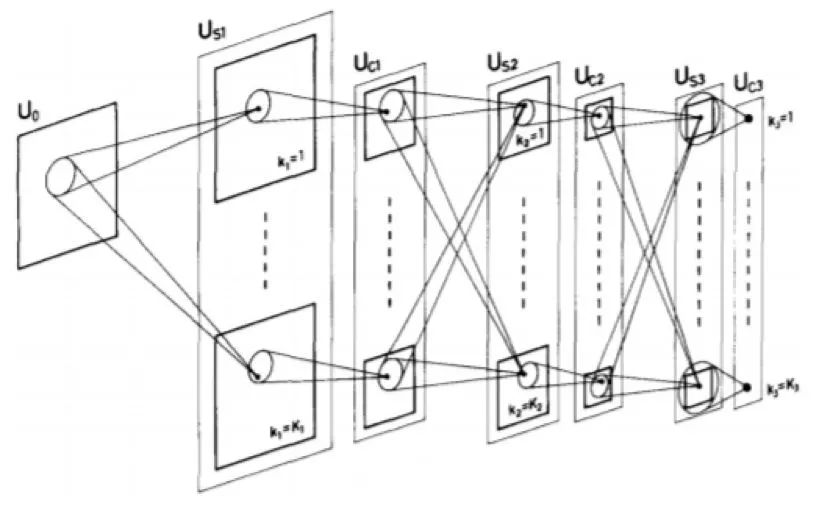
Figure 2.6: Schematic diagram of Neocognitron, drawing from [49]
2.1.4 Generation of confrontation network
A typical generational confrontation network (GAN) consists of two competing modules or subnetworks, namely: a generator network and a discriminator network.
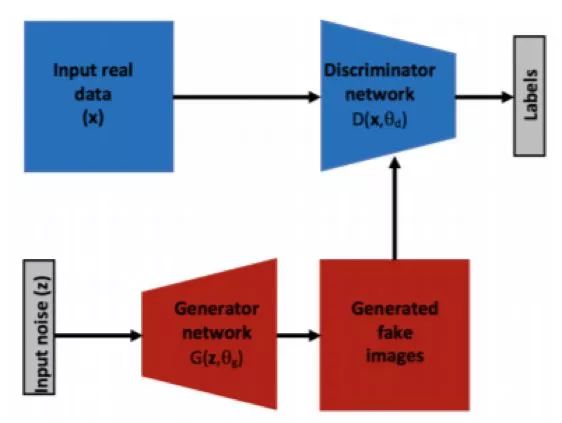
Figure 2.7: Schematic diagram of the general structure of the generated confrontation network
2.1.5 Multi-layered Network Training
As discussed earlier, the success of multiple multi-tier architectures depends largely on the success of their learning process. The training process is usually based on back propagation using gradient descent errors. Due to its ease of use, gradient descent has a wide range of applications in training multi-layer architectures.
2.1.6 Simply speaking about migration learning
The applicability of features extracted using multi-tiered architectures to a variety of different data sets and tasks can be attributed to their hierarchical nature. Characterization can evolve from simple and local to abstract and global in such structures. Therefore, the features extracted in the lower level of the hierarchy are often the features shared by many different tasks, thus making it easier for the multi-layer structure to realize the migration learning.
2.2 Space Convolutional Network
In theory, convolutional networks can be applied to any dimension of data. Their two-dimensional example is very suitable for the structure of a single image, and therefore has received considerable attention in the field of computer vision. With the large-scale data sets and powerful computers for training, CNN's recent applications in many different tasks have seen rapid growth. This section introduces the more prominent 2D CNN architecture that introduces relatively new components to the original LeNet.
2.2.1 Key Frameworks for CNN's Recent Development
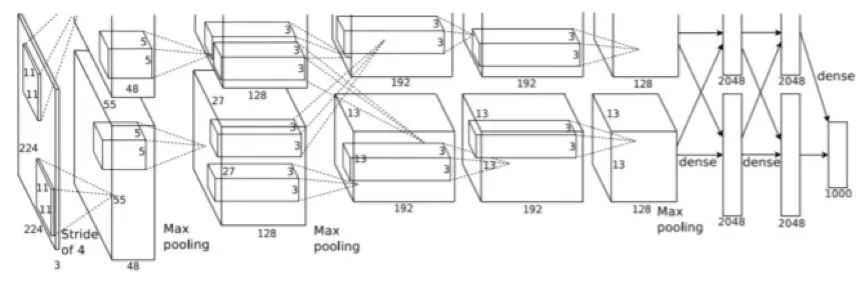
Figure 2.8: AlexNet architecture. It should be pointed out that although this is an architecture with two streams, it is actually a single-stream architecture. This diagram only shows how AlexNet works in parallel on two different GPUs. Picture from [88]
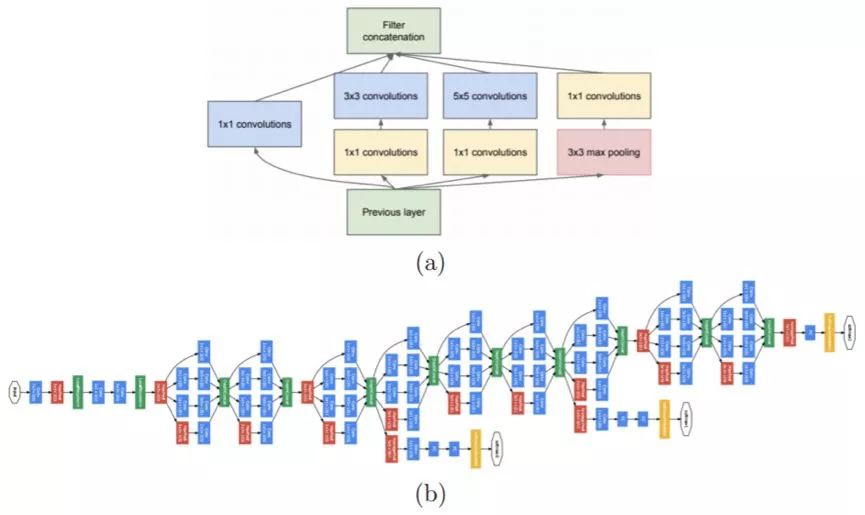
Figure 2.9: GoogLeNet Architecture. (a) A typical inception module that shows sequential and parallel operations. (b) Schematic diagram of a typical inception architecture consisting of a number of cascaded inception modules. Picture from [138]
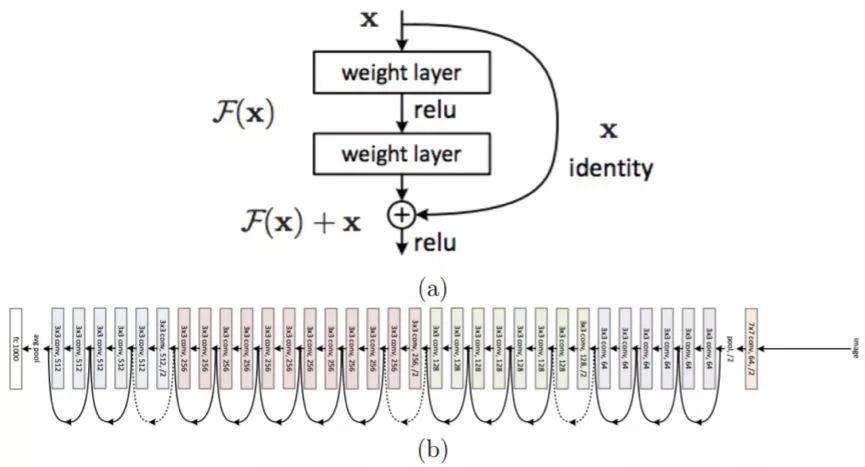
Figure 2.10: ResNet architecture. (a) Residual module. (b) A typical ResNet architecture diagram composed of many stacked residual modules. Picture from [64]
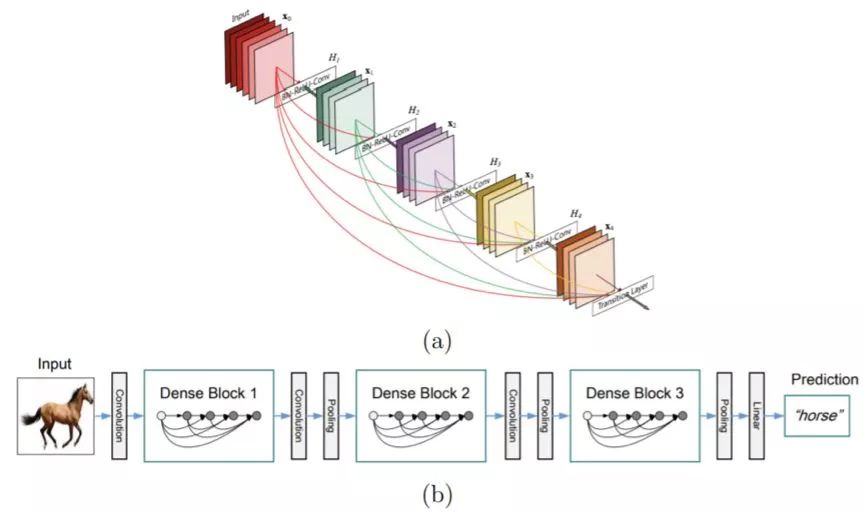
Figure 2.11: DenseNet Architecture. (a) The dense module. (b) (b) Schematic diagram of a typical DenseNet architecture consisting of a number of stacked dense modules. Picture from [72]
2.2.2 Instinctiveness of CNN
One of the big problems with CNN is that it requires very large data sets to learn all the basic parameters. Even large-scale data sets such as ImageNet with more than 1 million images are still considered too small when training a specific deep architecture. One way to satisfy this large data set requirement is to artificially enhance the data set. This includes random flipping, rotation, and jittering of the image. One of the great advantages of these enhancements is that they allow the resulting network to remain better when faced with various transformations.
2.2.3 Implementing CNN Positioning
In addition to simple classification tasks such as object recognition, CNN has recently performed well on tasks that require precise positioning, such as segmentation and target detection.
2.3 Spatio-temporal convolutional network
The use of CNN has brought significant performance improvements to various image-based applications, and has also given rise to researchers' interest in extending 2D spatial CNN to 3D spatio-temporal CNN for video analytics. In general, the various spatio-temporal architectures proposed in the literature are merely attempts to extend the 2D architecture of the spatial domain (x,y) into the time domain (x, y, t). There are three more prominent architectural design decisions in the training-based space-time CNN domain: LSTM-based CNN, 3D CNN, and Two-Stream CNN.
2.3.1 Space-time CNN Based on LSTM
LSTM-based spatio-temporal CNNs are some early attempts to extend 2D networks into spatio-temporal data. Their operation can be summarized in three steps shown in Figure 2.16. In the first step, each frame is processed using a 2D network, and feature vectors are extracted from the last layer of these 2D networks. In the second step, these features from different time steps are used as input to the LSTM to get a temporal result. In the third step, these results are averaged or linearly combined and then passed to a softmax classifier for final prediction.
2.3.2 3D CNN
This prominent spatio-temporal network is the most direct generalization of 2D CNN into image space-time domain. It processes the time streams of RGB images directly and processes these images by applying learned 3D convolution filters.
2.3.3 Two-Stream CNN
This type of spatio-temporal architecture relies on a two-stream design. The standard two-stream architecture uses two parallel paths—one for processing the appearance and the other for processing the movement; this approach is similar to the two-stream assumption in biological vision system research.
2.4 Overall discussion
It is important to point out that although these networks have achieved very competitive results in many computer vision applications, their main drawbacks still exist: the understanding of the exact nature of the characterizations learned is limited and dependent on large Scale data training sets, lack of ability to support accurate performance boundaries, and network hyperparameter selection are not clear.
03 Understanding CNN's Building Blocks
Given the large number of outstanding issues in the CNN domain, this chapter will introduce the role and significance of each processing layer in a typical convolutional network. For this purpose, this chapter will outline the most prominent work in solving these problems. Particularly worth mentioning is that we will demonstrate the modeling of CNN components from both theoretical and biological perspectives. The introduction of each component is followed by a summary of our current level of understanding.
3.1 Convolution layer
The convolutional layer can be said to be one of the most important steps in the CNN architecture. Basically, convolution is a linear, translation-invariant operation that consists of a combination of performing local weighting on the input signal. Depending on the selected set of weights (ie, the point spread function chosen), different properties of the input signal will also be revealed. In the frequency domain, associated with the point spread function is the modulation function - which illustrates how the frequency components of the input are modulated by scaling and phase shift. Therefore, choosing the right kernel is crucial for obtaining the most significant and important information contained in the input signal, which allows the model to make better inferences about the content of the signal. This section discusses some of the different ways to implement this nuclear selection step.
3.2 Rectification
Multi-layer networks are usually highly nonlinear, and rectification is usually the first stage of the process of introducing nonlinearity into the model. Rectification refers to the application of a non-linear point of view (also known as an activation function) to the output of a convolutional layer. This term is borrowed from the field of signal processing where rectification refers to converting AC to DC. This is also a processing step that can find causes in both biological and theoretical aspects. The purpose of computational neuroscientists' introduction of rectification steps is to find a suitable model that best explains the current neuroscience data. On the other hand, the purpose of using rectification by machine learning researchers is to make models learn faster and better. Interestingly, researchers in both areas often agree with this point: they not only need to rectify, but they also go to the same type of rectification.
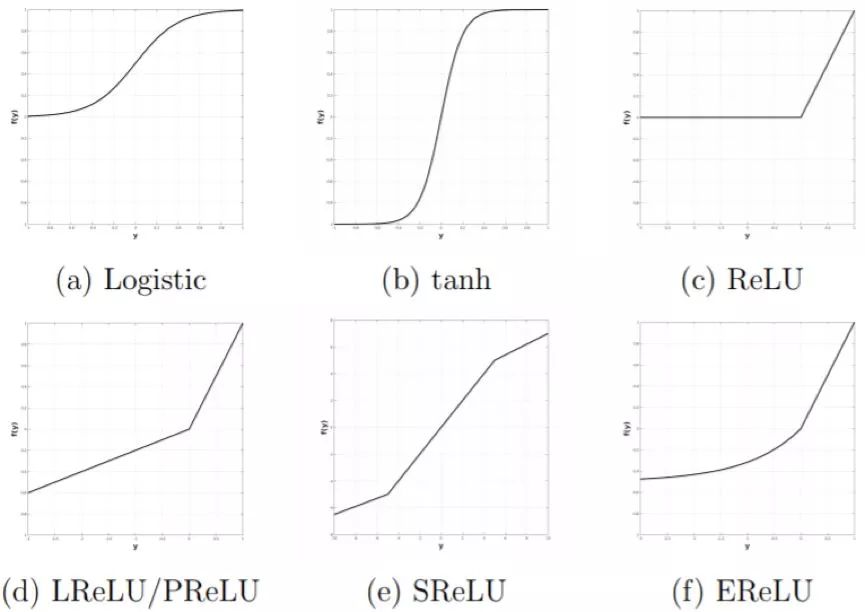
Figure 3.7: Nonlinear Rectification Functions Used in Literature for Multilayer Networks
3.3 Normalization
As mentioned earlier, the multilayer architecture is highly non-linear due to the cascaded non-linear operations in these networks. In addition to the rectification nonlinearity discussed in the previous section, normalization is another nonlinear processing module that plays an important role in the CNN architecture. The most widely used normalized form in CNN is the so-called Divisive Normalization (DN, also referred to as partial response normalization). This section will introduce the role of normalization and describe how it corrects the shortcomings of the first two processing blocks (convolution and rectification). Similarly, we will discuss the normalization from two aspects of biology and theory.
3.4 Pooling
Whether biologically inspired or purely based on learning or completely artificially designed, almost all CNN models include a pooling step. The goal of pooling operations is to bring about a certain degree of invariability to changes in position and size and to aggregate responses within and across feature maps. Similar to the three CNN modules discussed in the previous sections, pooling supports both biological and theoretical research. At this level of processing at the CNN network, the main issue is the choice of pooling functions. The two most widely used pooling functions are average pooling and maximum pooling. This section explores the advantages and disadvantages of the various pooling functions described in the relevant literature.

Figure 3.10: Comparison of average pooling and maximum pooling on Gabor filtered images. (a) Demonstrate the effect of average pooling at different scales, where the upper row in (a) is the result of the application of the original grayscale value image, and the lower row in (a) is the result of applying the Gabor filtered image. The average pooling yields a smoother version of the grayscale image, while the sparse Gabor filtered image fades. In contrast, (b) gives the maximum pooling effect at different scales, where the upper row in (b) is the result of applying the original grayscale image, and the lower row in (b) is applied after Gabor filtering. The result on the image. It can be seen here that the maximum pooling will result in a decrease in the grayscale image quality, while the sparse edges in the Gabor filtered image will be enhanced. Picture from [131]
04 Current status
The discussion of the role of various components in the CNN architecture highlights the importance of the convolutional module, which is largely responsible for obtaining the most abstract information in the network. Relatively speaking, we have the least understanding of this processing module because it requires the most tedious calculations. This chapter will introduce current trends in trying to understand what the different CNN layers learn. At the same time, we will also highlight the issues that remain to be resolved in these trends.
4.1 Current trends
Although various CNN models continue to advance the current best performance in a variety of computer vision applications, the progress in understanding how these systems work and why they are so effective is still limited. This issue has attracted the interest of many researchers, and a lot of methods for understanding CNN have emerged for this purpose. In general, these methods can be divided into three directions: visualization of the learned filters and extracted feature maps, an ablation study inspired by the understanding of biological methods of the visual cortex, and introduction of analysis principles into the network design. Minimize the learning process. This section will briefly outline each of these methods.
4.2 Problems to be Solved
Based on the above discussion, the following key research directions exist for the visualization-based approach:
First and foremost: Developing methods that make visual assessments more objective is very important and can be achieved by introducing indicators that evaluate the quality and/or meaning of the generated visual images.
In addition, although it seems that network-centric visualization methods are more promising (because they are not dependent on the network itself for generating visualization results), it seems necessary to standardize their assessment processes. One possible solution is to use a benchmark to generate visualizations for a network trained under the same conditions. Such standardized methods, in turn, can also achieve index-based assessment rather than current interpretive analysis.
Another development direction is to visualize multiple units at the same time to better understand the distributed aspects of the characterization being studied, and even follow a controlled approach at the same time.
The following are potential research directions based on the ablation study:
Use a common system-organized data set with different challenges common in the field of computer vision (such as perspective and light changes), and also require more complex categories (such as texture, component, and target complexity) . In fact, such datasets have recently appeared [6]. Using an ablation study on such a data set, together with an analysis of the resulting confusion matrix, can determine the pattern of errors in the CNN architecture and achieve a better understanding.
In addition, a systematic study of the way in which multiple collaborative ablation affects the performance of the model is of interest. Such research should extend our understanding of how independent units work.
Finally, these controlled methods are promising future research directions; because these methods allow us to have a more in-depth understanding of the operation and characterization of these systems than a completely learning-based approach. These interesting research directions include:
Gradually fix the network parameters and analyze the impact on network behavior. For example, a constant layer of convolution kernel parameters (based on prior knowledge of the task already available) is used to analyze the suitability of the applied core at each layer. This progressive approach is expected to reveal the role of learning, but it can also be used as an initialization method to minimize training time.
Similarly, the design of the network architecture itself (such as the number of layers or the number of filters in each layer) can be studied by analyzing the nature of the input signal (such as common content in the signal). This approach helps to make the architecture reach the appropriate application complexity.
Finally, the use of controlled methods in the implementation of the network can be a systematic study of the role of other aspects of CNN. Due to the learning parameters that people focus on, this aspect receives less attention. For example, it is possible to study the effects of various pooling strategies and residual connections when most of the learned parameters are fixed.
DLP Home Projecror-The principle is mainly to switch the light through the control of the micro-mirror, so as to realize the color scale and gray scale. On the small DMD chip, there are nearly a million small mirrors that are smaller than the hair The advantages of DLP projectors are: long service life and fast response speed
Dlp Home Projecror,dlp projector remote,dlp projector portable,dlp 1080p projector,dlp projector 4k
Shenzhen Happybate Trading Co.,LTD , https://www.szhappybateprojectors.com