Introduction: Differentiating between different people is an essential capability of many intelligent systems. The so-called face recognition technology is also developed for this purpose. It uses the optical imaging of human faces to sense people and identify people . After decades of research and development accumulation, especially the emergence of deep learning technology in recent years, face recognition has made great progress, and has been increasingly used in security, finance, education, social security and other fields, and has also become a computer vision. One of the most successful branch areas in the field.
However, face recognition is not a completely mature technology. It is still far from the full application of public expectations. It still requires the joint efforts of the academic and industrial communities. For this reason, the entire face recognition community needs a Baseline system, and the level of the reference system will obviously have a great influence on the level of development in this field. However, what is embarrassing is that there is no set of completely open source reference face recognition systems including all technology modules in this field. The latest open-source Seeta Face facial recognition engine may be able to change this situation. The engine code was developed by the Face Recognition Research Group led by Shan Shiguang's researcher at the Institute of Computing, Chinese Academy of Sciences. The code is based on C++ and does not depend on any third-party library functions. The open-source protocol is BSD-2, which can be freely used by academia and industry.
The SeetaFace face recognition engine includes the three core modules needed to build a fully automated face recognition system:
Face Detection Module SeetaFace Detection
Facial feature point positioning module SeetaFace Alignment
Face feature extraction and comparison module SeetaFace Identification
Among them, the face detection module SeetaFace Detection adopts a cascade structure combining traditional man-made features and a multilayer perceptron (MLP), achieving an 84.4% recall rate (100 false detections) on the FDDB, and Real-time processing of VGA-resolution images on a single i7 CPU.
The facial feature point finding module SeetaFace Alignment returns the position of five key feature points (two-eye center, nose tip, and two mouth corners) by cascading multiple depth models (stacked self-encoding network) to achieve state-of on the AFLW database. -The accuracy of the-art, positioning speed exceeds 200fps on a single i7 CPU.
The face recognition module SeetaFace Identification uses a 9-layer convolutional neural network (CNN) to extract facial features and achieve 97.1% accuracy on the LFW database. (Note: SeetaFace face detection and SeetaFace facial feature point positioning are used as the front end. In the case of fully automatic recognition), the feature extraction speed is 120ms per picture (on a single i7 CPU).
Below to briefly understand the above three core modules, more detailed information can refer to the relevant reading.
| Face Detection SeetaFace Detection
The face detection module SeetaFace Detection is based on a face detection method combined with a classical cascade structure and a multi-layer neural network. The funnel-structured cascade (FuSt) is used for multi-pose face detection. The design, which introduced a design concept from coarse to fine, balanced both speed and accuracy. As shown in FIG. 1, the FuSt cascade structure is composed of a plurality of fast LAB cascade classifiers for different poses at the top, followed by several SURF-based multi-layer perceptron (MLP) cascade structures, and finally by one. The unified MLP cascade structure (also based on the SURF feature) handles the candidate windows of all poses, and overall presents a narrow upper funnel shape. From top to bottom, the classifiers at each level and their adopted features gradually become complex, so that the face window can be preserved and non-face candidate windows that are more and more difficult to distinguish from faces can be excluded.
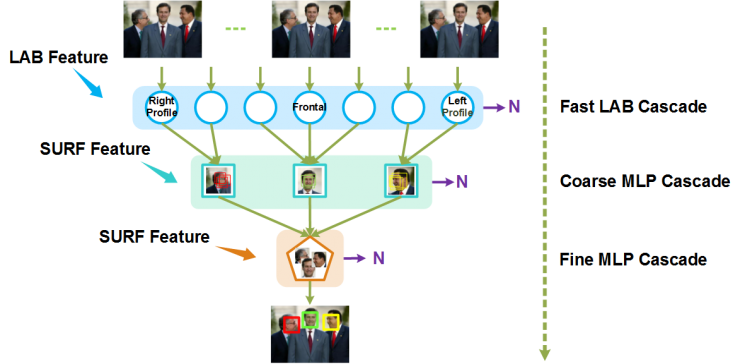
Figure 1. FuSt funnel cascade structure used by SeetaFace face detection module
Opened with the SeetaFace Detection open source code is a quasi-frontal face detection model (using about 200,000 face images trained) that can accurately detect the quasi-frontal face (rotation angle of about 45 degrees, but for the gesture Larger deflection faces also have certain detection capabilities. Figure 2 shows some examples of test results. (Note: The downscale ratio of the image pyramid is set to 0.8 during the test, and the slide step length is set to 4 and 2, the smallest face Set to 20x20).
The SeetaFace Detector was evaluated on the most important evaluation set FDDB in the field of face detection. The recall rate reached 84.4% when 100 errors were detected (FPPI=0.035), and the recall rate reached 88.0% when 1000 errors were output. Figure 3 shows the discrete score ROC curve of the SeetaFace Detector on the FDDB and compares it with other published published results of the academic community (obtained from the FDDB website). It is not difficult to see that although the Seeta Face face detector is not currently the most accurate, it still has strong competitiveness in the academically disclosed results and can fully satisfy the needs of most face recognition systems.

Figure 2. Example of SeetaFace Detection face detection results
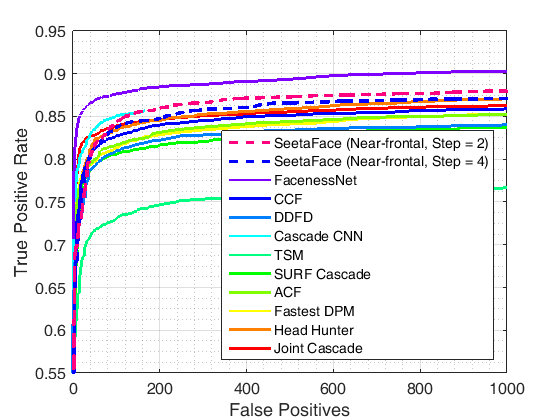
Figure 3. ROC curve of SeetaFace Detector on FDDB
In addition, SeetaFace Detector has a certain speed advantage over other algorithms. For the 640x480 VGA image, the comparison of the detection speed is shown in Table 1. Among them, the Speed ​​of SeetaFace was measured on a single 3.40GHz i7-3770 CPU, and the speed of the Cascade CNN on a CPU was measured on a 2.0GHz CPU (quoted from the original). The speed of each method on the GPU is measured on the NVIDIA Titan Black GPU.

Table 1. Detection speed of SeetaFace Detector and comparison with other methods
Note: The SeetaFace Detector's sliding window step is set to 4 and the image pyramid's downsampling step is set to 0.8. On the other hand, Cascade CNN has an image pyramid downsampling step of 0.7 (the corresponding scale factor is 1.414).
| Positioning Feature Points SeetaFace Alignment
Facial feature point positioning (face alignment) plays a very important role in face analysis tasks such as face recognition, face recognition, and face animation synthesis. Due to the influence of gestures, expressions, lighting, and occlusion, the face alignment task in real scenes is a very difficult problem. Formally, this problem can be seen as a complex non-linear mapping from face appearance to face shape.
To this end, SeetaFace Alignment uses a Coarse-to-Fine Auto-encoder Networks (CFAN) proposed by us to solve this complex nonlinear mapping process. As shown in FIG. 4 , the CFAN cascades a multi-level stacked self-encoder network, each of which depicts a partial non-linear mapping from the human face appearance to the human face shape. Specifically, a face area is input (obtained by the face detection module), and the first level self-encoder network quickly estimates the approximate face shape S0 from the low-resolution version of the face.
Then, the resolution of the input face image is increased, and the local features of the respective feature point positions of the current face shape S0 (correspondingly increased resolution) are extracted and input to the next-level self-encoder network to further optimize the face alignment result. By analogy, the cascaded multiple self-encoder networks are used to gradually optimize face alignment results on higher and higher resolution face images.
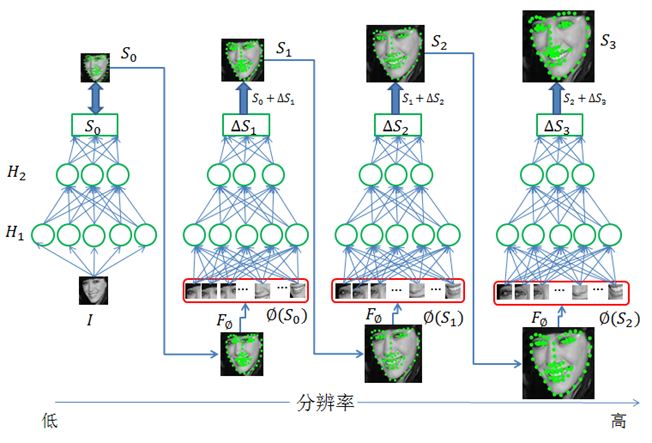
Figure 4. Real-time face alignment method based on coarse-to-fine self-encoder network (CFAN)
The open source Seeta Face Alignment achieved accurate positioning of five key facial feature points (two eye centers, nose tips, and two mouth corners) based on the above CFAN method. The training set included more than 23,000 facial images (with 5 points marked). It should be noted that, for the purpose of acceleration, the number of CFAN cascades has been reduced to level 2 in an open source implementation without any loss of accuracy, which can be achieved on a single Intel i7-3770 (3.4 GHz CPU). Personal face 5ms processing speed (excluding face detection time).
Figure 5 shows some examples of using the Seeta Face Alignment open source engine to locate the facial 5 points. It can be seen that it has good robustness to facial expressions, gestures, and skin color. The quantitative evaluation and comparison on the AFLW data set are shown in Fig. 6, where the average positioning error is normalized based on the distance between the two eyes. It's easy to see that SeetaFace Alignment has achieved state-of-the-art positioning results.

Figure 5. Example of SeetaFace Alignment positioning results
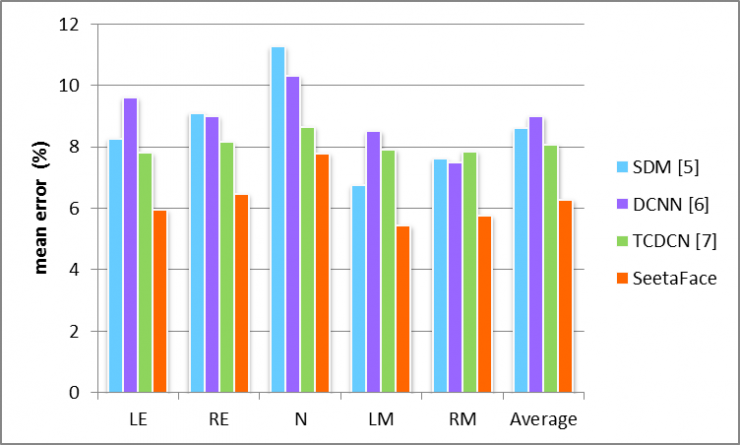
Figure 6. Positioning error and comparison of SeetaFace Alignment on AFLW dataset
Among them, LE: left eye, RE: right eye, N: nose tip, LM: left mouth corner, RM: right mouth corner
| Feature Extraction and Comparison of Faces SeetaFace Identification
Face recognition is essentially to calculate the degree of similarity of human faces in two images. It can be roughly divided into:
Registration phase (analogous person's acquaintance process) input system
Recognition stage (that is, recognition process during goodbye) input
For this purpose, as shown in FIG. 7 , after completing the aforementioned two steps of face detection and face alignment, a fully automatic face recognition system enters the third core step: face feature extraction and comparison. This stage is also the most advanced module after deep learning has been surging. At present, most excellent face recognition algorithms use Convolutional Neural Networks (CNN) to learn feature extractors (ie, function F in FIG. 7).
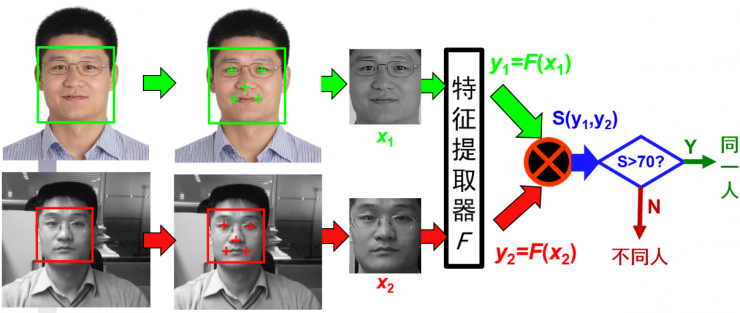
(1) Face detection (2) Key point alignment and face alignment (3) Face feature extraction, comparison and determination
Figure 7. Core process of face recognition system
The SeetaFace open source facial feature extraction module is also based on convolutional neural networks. Specifically, it implements the deep convolutional neural network VIPLFaceNet described in the article: a DCNN containing 7 convolution layers and 2 full connectivity layers. It was directly modified by Professor Hinton's student Alex Krizhevsky who was equal to AlexNet designed in 2012 (that is, the network that detonated CNN's widely used vision).
As shown in the comparison of Table 2, compared with AlexNet, VIPLFaceNet splits the 5x5 convolution kernel into two 3x3 convolution kernels, which increases the network depth without increasing the amount of computation; VIPLFaceNet also reduces each volume. The number of stacked kernels and the number of FC2 nodes.
At the same time, by introducing the Fast Normalization Layer (FNL), the convergence speed of VIPLFaceNet is accelerated, and the generalization ability of the model is improved to some extent. Tests show that in the same training set, VIPLFaceNet reduced the recognition error rate on the LFW test set by 40% compared to AlexNet, while training and testing time were 20% and 60% of AlexNet, respectively.
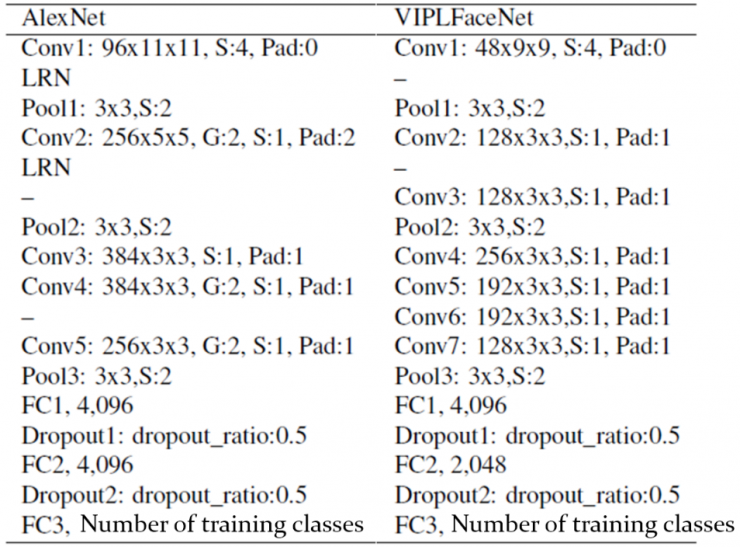
Table 2. Comparison of VIPLFaceNet and AlexNet network structures used by SeetaFace Identification
The face recognition model released with the open-source SeetaFace Identification code was trained using 1.4 million face images. These training images came from about 16,000 people, including both Orientals and Westerners. The facial features directly use the output of 2048 nodes of the VIPLFaceNet FC2 layer. The feature comparison can simply use Cosine to calculate the similarity, and then perform threshold comparison (verification application) or sorting (identification application).
The engine has good performance in most face recognition scenarios. For example, under the LFW standard Image-Restricted test protocol, faces are detected and aligned using Seeta Face Detector and Seeta Face Alignment, and feature extraction and comparison are performed using Seeta Face Identification. 97.1% recognition accuracy (please note: this is the result of the system fully automatic operation, for a small amount of images can not be detected in the face, intercept the middle area to enter the face alignment module can be). In terms of speed, on a single Intel i7-3770 CPU, the open source code takes about 120ms to extract the features of a human face (without face detection and feature point positioning time).
Related reading:
Currently, the SeetaFace open source face recognition engine has all been published on Github for use by domestic and foreign counterparts and industry. The project's website is: http://github.com/seetaface
The image from The Matrix
Electric Slip Ring,Slip Rings In Generator,Flat Disc Electrical Slip Ring,Slip Ring Electric Motor
Dongguan Oubaibo Technology Co., Ltd. , https://www.sliprob.com