
Editor's Note: The author Pedro Eugênio Rocha is currently a Facebook Systems Engineer. He graduated from the Federal University of Parana State in Brazil in 2016 with a major in Informatics. His research interests include databases and storage systems, especially databases and storage systems related to distributed systems and big data. The author introduces Cubrick in the article: A multidimensional memory data management system. Cubrick is a new type of distributed multidimensional in-memory database management system developed by Facebook. Its purpose is to solve the problems of parallel operation of a large number of data resources. To achieve the goal of interactively analyzing highly dynamic data sets, Cubrick uses a new strategy for managing cylindrical memory data that allows index filtering in each dimension of the dataset and effectively updates in real time.
Real-time analysis of large data sets has become a widespread demand of many Internet companies. Minimizing the time difference between data generation and data analysis enables data-driven Internet companies to form insights and make decisions in a timely manner, which ultimately promotes rapid growth. In order to realize real-time analysis, a database system needs to be built to ensure that the system can continuously obtain the data stream generated by the network log and respond to the query request after a few seconds of data generation. Given that there are real-time data streams that can release millions of records per second, large-scale acquisition of these highly dynamic data sets will face increasing challenges.
In addition, all database queries need to be completed in hundreds of milliseconds to provide users with a truly interactive experience in order to fully exploit the value of the data, but in fact, browsing large data sets in such a short time requires a lot of Running in parallel, huge data resources become necessary hardware conditions. However, in the work of Facebook over the past few years, we have observed some practical cases in which all the queries have been over-filtered. In addition, we only focus on a small subset of specific subsets of very large data sets . For example, a query may be only interested in one metric in a particular demographic, for example, limited to people living in the United States, or from a specific gender, measuring session volume, querying a specific Groups, or mentioning a particular tag. Considering which filter conditions apply depends on which parts of the data set the data analyst is interested in. Such filter conditions are mostly point-to-point, making the traditional one-dimensional predefined index less effective.
Cubrick is a new type of distributed multidimensional in-memory database management system developed by Facebook. Its purpose is to solve the problems of parallel operation of a large number of data resources. To interactively analyze highly dynamic data sets, Cubrick uses a new strategy for managing cylindrical memory data that allows index filtering in each dimension of the dataset and effectively updates in real time. This data management strategy combined with a special and optimized query engine makes Cubrick the only data management system that is suitable for interactive real-time analysis, and has enabled Cubrick to achieve the data management scale that is not yet achieved in current database solutions.
This week New Delhi, India top international database conferences (VLDB) on our upcoming presented papers Cubrick: Indexing Millions of Records per second for Interactive Analytics article, we describe the named Granular Partitioning of Cubrick new data management technology, introduces the Cubrick The internal data structure, distributed model and query execution engine, and will announce the current Facebook application of this new data management system.
The application of Cubrick
Traditional database techniques that improve filtering performance by skipping non-essential data are either based on maintaining indexes (auxiliary data structures) or based on pre-finishing data sets. Increasing the efficiency of obtaining a particular record by maintaining secondary indexes (such as B+Trees) is a well-known technique used for most data management systems, and almost every type of OLTP data management system uses this database technology. However, in OLAP workloads, the logarithmic overhead of maintaining an updated index is prohibited due to being considered as a measure of the size of the table and the rate at which data is obtained. In storage traces, most types of indexes (known as secondary indexes) store intermediate nodes and data pointers by increasing the amount of memory they occupy, so that indexing each column may result in storage usage. multiply. In addition, how to accurately determine the index bar is a challenge for point-to-point queries.
Another way to effectively skip data during the query time is to pre-define the data set . A column-oriented database built on the C-STROE architecture can maintain multiple replicated versions of datasets sorted by keywords - also known as maps - and can also be used to effectively evaluate each of the sorted by keyword. Filter performance in the bar. Although a structure similar to LSM-Tree (merge tree of the log structure) is used to apportion the computational cost of the insertion, as the scale of the acquired data continues to increase, a large amount of data reorganization is still required to ensure the mapping result. Real-time updates. In addition, we have to decide in advance which sorting machines we want to create, which are difficult to define in a data set made up of point-to-point queries. Finally, because each new mapping is a copy of the entire data set, this approach does not apply to the memory settings of the data management system. This data management system tries to fit as many data sets as possible in its memory. Avoid heavy access to the hard disk.
A new method
We have adopted a new method to solve the problem of skipping non-essential data to improve filter performance, instead of pre-sorting data sets or maintaining secondary index data structures. Assuming that all tables in the system are partitioned by each dimension column, we extend the concept of traditional database partitioning. At the same time, the cardinality of each dimension column can be obtained in advance, which allows us to understand the data set as a large cube with a smaller hypercube, to a certain extent more like an n-dimensional cube. Each smaller hypercube (or brick, Cubrick terminology) represents an identifier assigned by the cardinality function, and stores data in each column in an unordered and annotated form. Finally, we assume that all string values ​​are code-encoded and internally represented by monotonically increasing integers. This assumption allows us to develop an optimized, sophisticated database engine that runs only at the raw data level.
Similar to other multidimensional database systems, each column of Cubrick is defined by a measure or a dimension. These dimensions are usually used for filtering and grouping. Each measure is used in an aggregate function. Figure 1 illustrates how: in a dataset example consisting of two dimensions—interval and gender, a base of 4, change sizes of 2 and 1, and two measures—preferences and reviews—for each The module allocates data records.

Given that there is a continuous time function that maps each record to its matching target module, and the data in each module is arranged in an unordered manner, this simple but effective method of data management takes into account the very effective Record insertion. In addition, if no records are inserted in the search space, each module can easily match the query filter during the query period and be groomed.
Experimental results
In order to evaluate Cubrick's rate of acquiring records and the CPU used to acquire the recording channel, Figure 8 shows the number of records per second for each single node cluster compared to the CPU usage. This experiment draws the following conclusion: Even if the number of records acquired per second reaches 1 million, the CPU occupied by each single node cluster is still at a low level (20% or less) .
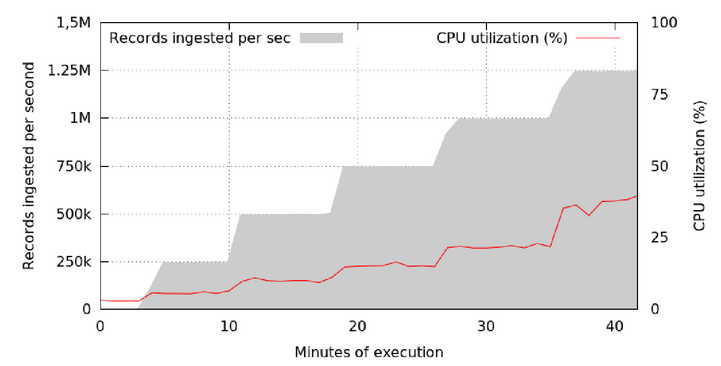
Note: The CPU usage of each single node cluster when acquiring records of different sizes
Figure 7 shows the multiple potential queries that exist for a 10TB data set running at a 72 node cluster to assess whether our indexing strategy is valid. The X axis represents the column to which the filter is applied, and the color scale is the filter's limitations, or the percentage of matching between the data set and the filter. The experimental results show that there is a clear correlation between the color and position on the Y-axis and no correlation with the position on the X-axis. In other words, regardless of the column, the query rate will be greatly improved when using filters.
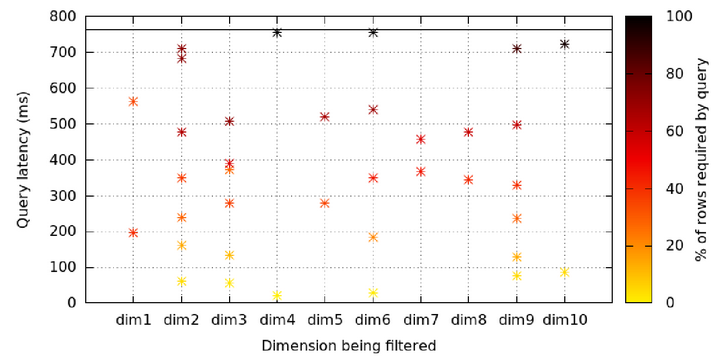
Note: There are multiple potential queries for a 10TB data set running at a 72-node cluster filtered through different dimensions
Please refer to our paper published at the 2016 International Top Database Conference for complete experimental methods and results.
Looking to the future
In the past few years, Facebbook has used Cubrick in multiple real-time (batch) interactive analytics applications. Cubrick is rapidly growing into a more mature full-featured data management system. With regard to how to more effectively deal with datasets with different data distribution characteristics and to make this cube schema more dynamic, we need to conduct a lot of research and verification. We believe that Cubrick's R&D is our first step towards this goal. However, there are still several unexplored and interesting topics in the research field waiting for us to conduct research.
Related to this article VLDB'16 Papers Paper 1, Paper 2
This article is compiled by Lei Feng Network (search "Lei Feng Network" public number) exclusive compilation, refused to reprint without permission!
Ip20 Ultra Thin Hca Power,Ultra Thin Power Supply,Light Box Power,Constant Voltage Light Box Power
Jiangmen Hua Chuang Electronic Co.,Ltd , https://www.jmhcpower.com